Building a Biotech Threat Model: A Practical Step-by-Step Guide & Example Case Study
- Alex Rozn
- May 20, 2025
- 17 min read
Updated: Jan 15

Introduction
Healthtech companies face increasingly complex cybersecurity regulations, including FDA, MDR, and HIPAA. While the specific requirements differ, all emphasize proper security risk management - and by extension, threat modeling as a foundational activity.
As the FDA puts it, threat modeling should be performed “to inform and support the risk analysis activities… throughout the design process and inclusive of all medical device system elements.”
Similarly, MDR guidance highlights threat modeling as a systematic way to identify attack vectors and decompose systems to expose and prioritize vulnerabilities based on risk and safety impact.
The FDA also recommends that companies include threat modeling documentation in premarket submissions to demonstrate how risks have been identified and addressed across the system.
One of the most practical resources referenced by the FDA is the MITRE/MDIC Threat Modeling Playbook, described as “An educational resource that discusses the threat modeling process, different techniques, and provides fictional medical device examples.”
For CTOs and security leaders in healthtech, threat modeling often feels overwhelming, especially without concrete examples or a clear process to follow.
In this post, we’ll walk you through how to do it yourself using the MITRE/MDIC Threat Modeling Playbook as a guide. Our case study features GenomeWell, a fictional direct-to-consumer genomics company but the approach is easily adaptable to any biotech, medtech, or digital health platform.
A Practical Threat Modeling Example for Healthtech Teams
Case Study: Company Context
GenomeWell is a European direct-to-consumer (DTC) genetics company. Customers order a saliva kit, mail it back, and receive ancestry and health-trait reports via a web portal or mobile app. GenomeWell does not provide medical diagnoses; it offers genetic insights for wellness and research participation.
Period of expected use: One-off kit, but customers may revisit reports over time (data retained for 5 years unless deleted).
Medical capability: Informational / wellness - no clinical decision support.
Device invasiveness: None (saliva collection only). </aside>
Key facts about the product:
Intended use: Informational only (no clinical decision support)
Sample type: Saliva, collected via a home kit
Data retention: Reports and genomic data are stored for up to 5 years, unless the customer requests deletion
User behavior: One-time kit, but customers can revisit their reports or download raw data
Research participation: Users can opt in to share their anonymized data with research partners via OAuth-based integrations
This context sets the stage for modeling GenomeWell’s architecture, data flows, and regulatory surface.
Core Use Case
Sophie Müller, curious about her family roots and lactose-intolerance risk, orders a GenomeWell kit online. She spits into the tube, registers the unique barcode in the GenomeWell app, and ships the sample to the lab. After sequencing and cloud analysis, Sophie receives an email: her reports are ready. She logs in to explore ancestry maps, trait results, and can optionally share data for research or download raw genome files.
Core Technology
Layer | Key Elements |
Sampling kit | Pre-barcoded saliva tube with stabilizing buffer and prepaid return packaging |
Mobile / Web app | iOS, Android, and React web portal for registration, consent, and report viewing |
Logistics platform | Barcode-based tracking with third-party carriers; status pushed to user account |
Sequencing lab | Illumina NovaSeq instruments + LIMS; output FASTQ files uploaded to cloud |
Bioinformatics pipeline | Containerised workflow on AWS Batch/Kubernetes; variant calling + annotation |
Data lake / storage | Encrypted S3 buckets (raw FASTQ, BAM, VCF); Postgres for processed reports |
Reporting & APIs | GraphQL / REST APIs serve reports to apps; optional OAuth scopes for partners |
1. Threat Modeling Example: Mapping GenomeWell’s Architecture (What Are We Working On?)
The goal of this phase is to understand the full system: how it works, what it’s made of, and where it interacts with the outside world. We start from a high-level view and gradually zoom in on the components, services, and workflows that matter most for security and privacy.
If your team doesn’t already have architecture documentation, a great place to start is the C4 model, which helps break down systems into layers:
Level 1 – System Context Diagram: Who uses the system? What external services does it talk to?
Level 2 – Container Diagram: What services make up the system? How do they communicate?

1.1 High-Level System Context (C4 Level 1)
A System Context diagram is a good starting point for diagramming and documenting a software system, allowing you to step back and see the big picture. Draw a diagram showing your system as a box in the centre, surrounded by its users and the other systems that it interacts with.
Here’s what a C1-level System Context Diagram might look like for GenomeWell:
Actor / System | Purpose | Trust Level |
Customer (Sophie) | Orders kit, registers barcode, views reports. | Public / Internet |
GenomeWell Platform | Receives samples, analyses DNA, delivers reports. | Trusted Cloud Core |
Sequencing Lab | Wet-lab processing, produces FASTQ. | Restricted Lab Zone (private network) |
Third-Party Logistics | Moves kits; status webhooks. | External Integrated |
Research Partners / OAuth Apps | Access (pseudonymized) data with consent. | Partner |

This diagram shows the high-level structure of GenomeWell’s system, including its primary users and external systems. It establishes trust boundaries and highlights where data enters and leaves the platform - an essential step in threat modeling.
This high-level overview is sufficient to begin identifying general threats such as phishing, data leaks, or tampering. However, to produce a more actionable model, we now zoom into the internal components and data flows that power GenomeWell’s functionality. This is where Level 2 Diagram come in.
1.2 Container Diagram (C4 Level 2)
At this step, we zoom in and look at the system’s major components - what it’s made of, how services are deployed, and how they talk to each other.
The Container diagram shows the high-level shape of the software architecture and how responsibilities are distributed across it. It also shows the major technology choices and how the containers communicate with one another. It’s a simple, high-level technology focussed diagram that is useful for software developers and support/operations staff alike.
Breakdown of Application Containers
Web Application
React + Next.js frontend delivered via CDN. UI for registration, login, consent, and report viewing. Talks to Cognito and API Gateway.
Tech: React, Next.js, GraphQL/REST, HTTPS, OAuth 2.1 (PKCE)
Mobile Application
Cross-platform app built with Flutter. Supports login, biometric auth, report access, and push notifications. Connects to Cognito and backend APIs.
Tech: Flutter (Dart), Firebase Push, OAuth 2.1, HTTPS
Auth Service
Managed identity platform for login, MFA, and token issuance. Issues JWTs with custom claims.
Tech: AWS Cognito, OIDC, Hosted UI, OAuth 2.1, JWT
API Gateway
Exposes GraphQL and REST APIs to client apps. Validates JWTs, applies rate limits and CORS, and routes requests to backend logic.
Tech: AWS API Gateway, Lambda Authorizer, JWKS, WAF
Application Logic
Back-end business logic for user management, consent tracking, and report generation.
Tech: Node.js / Python (FastAPI), AWS Lambda
Notification Service
Sends alerts for report readiness, kit status, and consent updates via email, SMS, and push.
Tech: Amazon SNS, SES
PostgreSQL (RDS)
Relational database for users, kits, consents, and structured reports.
Tech: Amazon RDS (PostgreSQL), TLS, IAM auth, KMS encryption
S3 Object Storage
Stores genomic files and artifacts across the data lifecycle: raw FASTQ, processed VCF, downloadable PDFs.
Tech: Amazon S3, KMS encryption, IAM, Object Lock, Lifecycle Policies
CloudWatch / CloudTrail
Logs API calls, access patterns, and security-relevant events for compliance and forensics.
Tech: AWS CloudTrail, CloudWatch Logs, Elastic SIEM
Research Partners / OAuth Apps
External apps and research partners that access pseudonymized data via scoped API tokens, based on user consent.
Tech: OAuth 2.1, JWT, GraphQL/REST APIs
Now let’s connect these components and visualize the internal data flows.
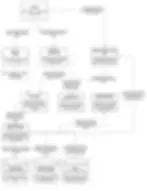
This diagram decomposes the GenomeWell platform into its key technical containers: frontend apps, backend logic, auth services, databases, object storage, observability, and external research APIs. It maps how data flows across services, with special focus on sensitive processing paths and trust boundaries.
Why stop here (and not go deeper)?
For initial threat modeling, C4 Level 3 and Level 4 diagrams are not required. The goal isn’t to document every function or class it’s to understand where sensitive data flows, what surfaces are exposed, and what trust assumptions exist between systems.
1.3 Data flow diagram (DFD)
Once we understand the system’s structure from a C4 perspective, we shift to modeling how data moves. This is where the Data Flow Diagram (DFD) comes in - a classic tool in threat modeling.
A Data Flow Diagram (DFD) is a structured modeling tool used to:
Visualize how data moves through a system
Show how external entities, processes, and data stores interact
Identify trust boundaries and potential threats
C4 vs. DFD: Complementary Views
While the C4 Model is ideal for understanding system components and responsibilities, the DFD focuses on data-centric risk analysis. Here’s how they compare:
Aspect | C4 Model | DFD |
Purpose | Show structure and ownership | Show how data flows and where it’s at risk |
Focus | Containers, services, interfaces | Data flows, sensitivity, trust boundaries |
Audience | Developers, architects, ops | Security, compliance, threat modelers |
Used For | System design, onboarding | Risk analysis, audit prep, threat identification |
To build our DFD, we adapted the C4 Level 2 diagram by applying DFD symbols, identifying sensitive data flows, and overlaying trust boundaries.

Understanding Trust Boundaries
💡 Trust boundaries are conceptual lines in your system architecture where the level of trust changes - typically between components, layers, users, or external systems.
Unlike data stores or services, trust boundaries are conceptual. They reflect security assumptions and help us ask:
"What if this component were compromised? What if the entity on the other side of this boundary is not trustworthy?"
Trust boundaries in the GenomeWell system
Trust Boundary | Description | Key Assets at Risk |
External Customer Zone | Interaction from untrusted user devices | Account data, credentials, PII |
Client App Zone | Executable code on end-user devices | App tokens, UI logic |
GenomeWell Cloud Core | Trusted backend under full control | Auth, business logic, reports |
External Partner Zone | OAuth apps and external research tools | Shared genomic data, consent records |
These boundaries help us focus threat modeling on interface surfaces and data flows that cross zones of differing trust - especially those exposed to the public or third parties.
DFD for GenomeWell
Having an architecture diagram already does 90% of the work - we just need to adapt it to DFD notation and add trust boundaries.

Where to go deeper next
The system-level DFD gives us an actionable overview, but certain high-value flows warrant focused modeling later:
Genomic data lifecycle — from FASTQ to VCF to downloadable report
Consent lifecycle — user opt-in, withdrawal, scope validation
OAuth-based data sharing — token-based access by research partners
Why stop here for now?
Since this is GenomeWell’s first formal threat modeling session, we’ve kept the scope at the system level.
This lets us focus on architecture-wide risks, external interfaces, and data exposure across trust boundaries - giving us the highest return on effort while laying the groundwork for deeper modeling in future iterations.
2. Identifying Threats Using STRIDE (What Can Go Wrong?)
In this section, we look for things that could go wrong in the system - such as mistakes, misuse, or technical weaknesses. Instead of trying to guess how an attacker might think, we focus on how the system is built and how it handles data. To guide this process, we’ll use the Data Flow Diagram (DFD) we created earlier. It helps us examine how data moves through the system, where it’s stored, and where trust boundaries exist - all of which are key to identifying potential security and privacy risks.
2.1 Starting with STRIDE
STRIDE is a structured framework for identifying six common types of security threats: Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege.
The simplest way to apply STRIDE is to go through each element in your DFD: external entities, processes, data stores, and data flows and ask: “Could this be affected by spoofing? tampering?”, and so on.
This structured method helps uncover threats without trying to simulate attacker behavior. It encourages you to consider real-world failure modes based on known threat types.
Below are the STRIDE categories, with simple definitions and real-world examples as
provided in the MITRE Playbook for Threat Modeling Medical Devices:
STRIDE Element | Description | Example |
Spoofing | Tricking a system into believing a falsified entity is a true entity | Using stolen or borrowed credentials to log in as another nurse |
Tampering | Intentional modification of a system in an unauthorized way | Changing patient data to incorrect values |
Repudiation | Disputing the authenticity of an action taken | Denying that a prescribed treatment was provided to the patient |
Information Disclosure | Exposing information intended to have restricted access | Health data sent over an unencrypted Bluetooth connection |
Denial of Service (DoS) | Blocking legitimate access or system functionality through malicious means | Flooding a Bluetooth sensor with bad requests, preventing real connections |
Elevation of Privilege (EoP) | Gaining unauthorized access to restricted functionality | A patient exploiting a vulnerability to see all patient records |
2.2 How We Apply STRIDE to the GenomeWell System
We followed a structured process based on the MITRE playbook:
Step 1: Create Two Tables to Track Threats
A matrix that maps system components and data flows to relevant STRIDE categories. Each cell contains a reference ID to a specific threat.
A supporting table that defines each threat by its reference ID.
Table 1 – STRIDE Threat Summary
Component / Data-flow | Spoof | Tamper | Repudiate | Info Disclosure | DoS | EoP |
Customer | 1, 2 | |||||
Web App (React) | 3 | 4 | ||||
Mobile App (Flutter) | 5 | 6 | 7 | 8 | ||
API Gateway | 9 | 10 | ||||
Auth Service (Cognito) | 11 | 12 | 44 | 13 | ||
Application Logic | 14 | 15 | 16 | |||
Notification Service | 17 | 18 | ||||
RDS Database | 19 | 20 | 21 | |||
S3 Object Storage | 23, 24 | 22, 43 | 42 | |||
Logs (CloudTrail / CW) | 25 | 26 | 27 | |||
Research / OAuth Apps | 29 | 28, 46 | 30 | |||
Dataflow Customer ↔ Web App | 31 | 43 | ||||
Dataflow Customer ↔ Mobile App | 44 | 45 | 32 | |||
Dataflow Apps ↔ API Gateway | 33 | 46 | ||||
Dataflow Apps ↔ Auth Service | 34 | |||||
Dataflow API Gw ↔ Auth Service | 35 | |||||
Dataflow API Gw ↔ App Logic | 36 | |||||
Dataflow App Logic ↔ RDS | 37 | 47 | ||||
Dataflow App Logic ↔ S3 | 38 | |||||
Dataflow App Logic ↔ Notification | 39 | |||||
Dataflow App Logic ↔ Logs | 40 | |||||
Dataflow Customer ↔ OAuth Consent | 48 | 41 | ||||
Dataflow Research Partner ↔ API | 42 | |||||
Dataflow Sequencing Lab ↔ S3 | 45 |
💡 What’s the difference between a component and dataflow in terms of threats?
They complement each other. One focuses on what can go wrong inside the code, the other on what can go wrong in the way it’s accessed or communicated with.
Table 2: STRIDE Threat Details
ID | STRIDE | Component / Data-flow | One-line Threat Description |
1 | Spoofing | Customer | Stolen credentials let someone sign in as a real user. |
2 | Spoofing | Customer | Phishing page tricks a user into giving away credentials. |
3 | Info Disclosure | Web App (React) | Tokens / data leak from browser storage or source maps. |
4 | EoP | Web App (React) | Hidden UI flags enable admin-only features. |
5 | Spoofing | Mobile App (Flutter) | Fake/rooted app forges device identity & session tokens. |
6 | Tampering | Mobile App (Flutter) | Modified APK intercepts or alters API traffic. |
7 | Info Disclosure | Mobile App (Flutter) | Sensitive data stored unencrypted on device. |
8 | EoP | Mobile App (Flutter) | Local flag edit unlocks screens for other roles. |
9 | Info Disclosure | API Gateway | Verbose errors reveal internal stack traces / schema. |
10 | DoS | API Gateway | Burst traffic exhausts rate limits & blocks real users. |
11 | Spoofing | Auth Service (Cognito) | Services accept JWT issued to a different user. |
12 | Info Disclosure | Auth Service (Cognito) | Over-broad OAuth scope leaks extra profile data. |
13 | EoP | Auth Service (Cognito) | Mis-mapped IAM roles grant elevated rights. |
14 | Tampering | Application Logic | Un-validated fields change report owner or consent. |
15 | Repudiation | Application Logic | Missing audit logs let users deny revoking consent. |
16 | EoP | Application Logic | Broken auth-z lets one user read another’s results. |
17 | Info Disclosure | Notification Service | Email / push leaks report details to wrong address. |
18 | DoS | Notification Service | Flood of events exhausts SNS/SES quotas. |
19 | Tampering | RDS Database | Mis-scoped write access edits consent rows. |
20 | Info Disclosure | RDS Database | Weak IAM / no TLS exposes PII & genomic data. |
21 | DoS | RDS Database | Mass queries stall DB, blocking reports. |
22 | Info Disclosure | S3 Object Storage | Public / cross-account bucket leaks FASTQ / VCF. |
23 | Tampering | S3 Object Storage | No object-lock: files overwritten with fake genome data. |
24 | Tampering | S3 Object Storage | Unauthorized delete removes genome files; no backup. |
25 | Tampering | Logs | Insider deletes CloudTrail records to hide activity. |
26 | Repudiation | Logs | Missing correlation IDs let users deny actions. |
27 | DoS | Logs | Debug spam fills SIEM, dropping new events. |
28 | Info Disclosure | Research / OAuth Apps | Broad scope lets partner pull extra genomic data. |
29 | Spoofing | Research / OAuth Apps | Rogue app pretends to be approved partner. |
30 | EoP | Research / OAuth Apps | Token reuse hits admin-only endpoints. |
31 | Spoofing | Dataflow Customer ↔ Web App | Phishing site mimics GenomeWell web login. |
32 | Info Disclosure | Dataflow Customer ↔ Mobile App | No TLS-pinning: data sniffed on public Wi-Fi. |
33 | Tampering | Dataflow Apps ↔ API Gateway | MITM proxy alters JSON before backend. |
34 | Spoofing | Dataflow Apps ↔ Auth Service | Fake client ID tricks Cognito into issuing tokens. |
35 | Repudiation | Dataflow API Gw ↔ Auth Service | Token checks not logged; actions untraceable. |
36 | Info Disclosure | Dataflow API Gw ↔ App Logic | Sensitive payload fields logged to CloudWatch. |
37 | Tampering | Dataflow App Logic ↔ RDS | SQL-injection tweaks consent data. |
38 | Tampering | Dataflow App Logic ↔ S3 | Backend writes malicious VCF into bucket. |
39 | DoS | Dataflow App Logic ↔ Notif Svc | Event flood overloads queue, delaying alerts. |
40 | Info Disclosure | Dataflow App Logic ↔ Logs | User IDs stored in plaintext logs. |
41 | Info Disclosure | Dataflow Customer ↔ OAuth Consent | Open redirect leaks auth-code to rogue domain. |
42 | EoP | Dataflow Research Partner ↔ API | Partner reuses token to pull non-consenting data. |
43 | Info Disclosure | Dataflow Customer ↔ Web App | Auto-fill / DOM leaks expose sensitive input on shared PC. |
44 | Spoofing | Dataflow Customer ↔ Mobile App | Fake mobile app captures login credentials. |
45 | Repudiation | Dataflow Customer ↔ Mobile App | No mobile audit: user can deny giving consent. |
46 | Info Disclosure | Dataflow Apps ↔ API Gateway | Tokens/IDs in GET query string logged by proxies. |
47 | Info Disclosure | Dataflow App Logic ↔ RDS | Column-level ACLs missing; over-broad SELECTs. |
48 | Repudiation | Dataflow Customer ↔ OAuth Consent | Unsigned consent events let users deny sharing. |
42 | DoS | S3 Object Storage | Bulk-delete or ransomware wipes genome files; no object-lock. |
43 | Info Disclosure | S3 Object Storage (Insider) | Ops admin copies full bucket to personal account. |
44 | DoS | Auth Service (Cognito) | Sign-up/login flood exhausts Cognito quotas, blocking logins. |
45 | Tampering | Dataflow Sequencing Lab ↔ S3 | Compromised lab PC uploads corrupted FASTQ files. |
46 | Info Disclosure | Research Partner Re-ID Risk | Partner deanonymises users by combining VCFs with external data. |
Using Attack Trees (Optional Deep-Dive)
Each threat can be further broken down into step-by-step attacker actions using the Attack Tree method:
An attack tree is a structured diagram that shows how an attacker might reach a goal (e.g., unauthorized data access), with branches for different tactics or conditions.
Attack trees help:
Reveal critical attack paths for prioritizing mitigations
Translate abstract threats into technical and testable scenarios
We don’t go deeper into attack trees in this document, but if you're curious, start with Bruce Schneier’s original paper.
2.3 Documenting the Threat Model
Keeping documentation clear and lightweight ensures the threat model remains useful - not just a snapshot, but a living reference.
For GenomeWell, we use:
Spreadsheets
To manage the STRIDE matrix, threat descriptions, CVSS scores, and mitigation status - all tracked with reference IDs.
Diagrams
The C4 model and DFD are maintained alongside threat IDs so that engineers, auditors, and regulators can trace everything back to its visual origin.
This setup supports:
Collaboration with engineering and external stakeholders
Onboarding for new team members
Iteration and review as the system evolves
In Section 3, we’ll assess how severe each threat is and decide what to do about it - using CVSS scoring and FDA-aligned mitigation strategies.
3. Mitigation Planning (What Are We Going To Do About It?)
In the previous sections, we identified and documented a list of potential threats to the GenomeWell platform. Now, we’ll explain how we score their severity, select mitigation strategies, and track progress so that risk management becomes practical, auditable, and ready for engineering and regulatory follow-through.
3.1 Risk scoring with CVSS-MD
To prioritize threats in a consistent, evidence-based way, we use the Common Vulnerability Scoring System (CVSS v3.1) paired with the MITRE CVSS rubric for medical devices.
This deterministic method meets FDA expectations by avoiding subjective likelihood estimates and providing clear, reproducible scores.
We use the guided scoring tool from DeepArmor: 👉 CVSS Rubric Tool
Each threat is scored by answering a step-by-step rubric, which outputs a CVSS vector, a base score, and a qualitative severity rating.
Score | Severity | What we do |
9.0–10.0 | Critical | Fix immediately or formally accept with exec sign-off |
7.0–8.9 | High | Plan mitigation in the current cycle |
4.0–6.9 | Medium | Schedule a fix; monitor for changes |
0.1–3.9 | Low | Log, track, and revisit quarterly |
Sample CVSS Ratings
ID | Threat | CVSS Vector | Base Score | Severity |
22 | S3 bucket misconfig leaks FASTQ/VCF | AV:N/AC:L/PR:N/UI:N/S:C/C:H/I:H/A:N | 9.1 | Critical |
10 | API Gateway DoS via burst traffic | AV:N/AC:L/PR:N/UI:N/S:U/C:N/I:N/A:H | 7.5 | High |
31 | Phishing site harvests login credentials | AV:N/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:N | 8.8 | High |
We apply this scoring process to every Medium and High threat in our STRIDE table to support prioritization and traceability.
3.2 Choosing mitigation strategies
After scoring each threat, we assign one or more of the following mitigation strategies:
Strategy | What it means | When to use it |
Eliminate | Remove the threat by redesigning the system or removing the vulnerable feature entirely. | Best when possible without breaking key functionality. |
Mitigate | Reduce the threat’s impact or likelihood using security controls: input validation, rate-limiting, encryption, etc. | The most common and flexible strategy. |
Accept | Formally accept the risk due to low severity or disproportionate mitigation cost. Must be documented and reviewed. | For low-score or hard-to-exploit risks. |
Transfer | Shift the responsibility to a third party via contracts, SLAs, or insurance. | For partner, vendor, or cloud-provider risks. |
Many high-impact threats are addressed using layered mitigations e.g., rate limits + logging + consent verification and reinforced with detection, alerts, and forensics (CloudTrail, SIEM).
We track every threat in a central spreadsheet, linked to tickets (e.g., GitHub, JIRA), and monitored by security and engineering.
Mitigation Tracking (example)
ID | CVSS | Strategy | Mitigation Action | Owner | Status |
22 | 9.1 (Critical) | Eliminate + Contain | Block public ACLs on S3, enable Object Lock & versioning | Storage Team | Open |
10 | 7.5 (High) | Mitigate | Add WAF & rate-limit /register endpoint | DevOps | Planned |
31 | 8.8 (High) | Mitigate + Transfer | Add anti-phishing banner, enforce SPF/DMARC, harden DNS | Security | In Progress |
42 | 9.4 (Critical) | Transfer + Mitigate | Contractual scope limits + audit logging for research access | Legal / Security | Planned |
44 | 7.3 (High) | Eliminate | Throttle login endpoint + CAPTCHA to deter bot abuse | DevOps | In Progress |
20 | 6.8 (Medium) | Accept (w/ controls) | Use VPN + CloudTrail alerts to limit risk of exposed RDS access | CISO | Accepted |
We also track:
Due Date – when mitigation is expected
Verification Method – test, audit, or review method
Residual Risk Summary – what remains post-mitigation
Linked Ticket – ID in your tracking tool
This ensures every threat can be traced from ID → Score → Strategy → Action → Status.
3.3 Threat modeling as a lifecycle
Threat modeling doesn’t end once tables are filled. We treat it as an ongoing process, updated with each system change or regulatory review.
To keep it useful:
Quarterly reviews – Close resolved threats, re-score anything that’s changed
Traceability – Every threat maps to a DFD or component
Audit log – We log who made what decisions and when
Integration – Tickets, code reviews, and pipeline steps are linked to threat IDs and CVSS scores
This turns threat modeling into a living part of our SDLC not just an exercise for audits, but a tool to catch real risks before they ship.
4. Evaluating the Model & Next Steps (Did We Do A Good Job?)
Before we close this threat modeling cycle, we take a step back to reflect and answer two key questions:
Have we covered enough to freeze the model for engineering, QA, and regulatory use?
Is our threat modeling process working well, or are there gaps to improve in the next iteration?
4.1 Closure checklist
We use the MITRE Playbook’s evaluation criteria to check the quality and readiness of our work.
Question | Status | |
Completeness | Every component, data flow, and trust boundary has at least one STRIDE threat. | ✔ |
Clarity | Any team member can read and understand threats, CVSS scores, and mitigations. | ✔ |
Specificity | Mitigations include concrete actions (e.g., “Enable S3 Object-Lock,” “Rate-limit login to 10 RPS”). | ➖ Two Medium risks need detailed control descriptions |
Traceability | Every threat ID connects to a diagram element, a mitigation row, and a ticket. | ✔ |
Consistency | Terminology and threat IDs match across DFDs, tables, and JIRA. | ✔ |
Roles & Ownership | Every Critical/High threat has an assigned owner; some Medium entries still “TBD.” | ➖ |
Assumptions | Scope exclusions (e.g., sequencing lab, logistics) are clearly documented. | ✔ |
Rationales | Accepted or transferred risks include justification. | ➖ Two Low-risk threats need brief rationale text |
External validation scheduled | Pen-test and SBOM scan are planned. | ✔ (Q3) |
4.2 Overall assessment
We’ve met the “good job” threshold as defined in the MITRE Playbook and FDA-aligned guidance:
✅ All Critical and High threats are scored, assigned, and linked to mitigation plans
✅ All risks are traceable from diagram to threat to ticket
✅ The model is clear, actionable, and reviewable by engineering and compliance teams
➖ Minor gaps (in control detail and owner assignment) are acknowledged and tracked
Next steps
Finalize mitigation tasks for two Medium-severity threats (add control details).
Assign owners to all remaining “TBD” entries.
Revisit and update the model after the Q3 pen-test and SBOM review.
Use results to re-score threats, close resolved ones, and expand where needed.
With these follow-ups in place, we can confidently freeze this version of the threat model and integrate it into GenomeWell’s SDLC, audit trail, and regulatory submission materials.
Conclusion
Threat modeling doesn’t need to be overly complex or reserved for regulatory submissions.
As this GenomeWell case study shows, even a first-round effort can yield clear insights, prioritized threats, and actionable security improvements especially when grounded in structured tools like the C4 Model, Data Flow Diagrams, STRIDE, and CVSS-MD.
By focusing on real components, sensitive data flows, and trust boundaries, we were able to identify high-value risks early, document concrete mitigation plans, and ensure traceability from design to defense.
This isn’t a one-time activity. GenomeWell’s threat model is now a living asset - ready to evolve as the system changes, new features launch, or new threats emerge.
If you're building a product in the biotech, medtech, or health data space, you can use this approach as a template:
Start small.
Stay structured.
Anchor your process in tools the FDA and EU regulators already recognize.
If you’d like help adapting this model to your system, or want support building a threat model for an upcoming audit or submission, submit a request or book a call here.
About the Author
Alex Rozhniatovskyi is the CTO of Sekurno, where he leads application security and threat modeling initiatives for healthtech and SaaS companies. With over 7 years of experience in software development and cybersecurity, he brings a practical, engineering-first approach to security architecture. His work focuses on bridging the gap between development and security translating technical complexity into clear, actionable strategies for builders and regulators alike.
References
MITRE. Playbook for Threat Modeling Medical Devices. PDF, 2021.
FDA. Cybersecurity in Medical Devices: Quality System Considerations and Content of Premarket Submissions (Final Guidance). PDF, 2023.
MITRE. Rubric for Applying CVSS to Medical Devices. Web, 2021.
DeepArmor. Guided CVSS-MD Rubric Tool. Web.
NIST. SP 800-30 Rev. 1: Guide for Conducting Risk Assessments. PDF, 2012.
C4 Model by Simon Brown. https://c4model.com